первую LLM с триллионным масштабом, полностью обученную на китайских чипах
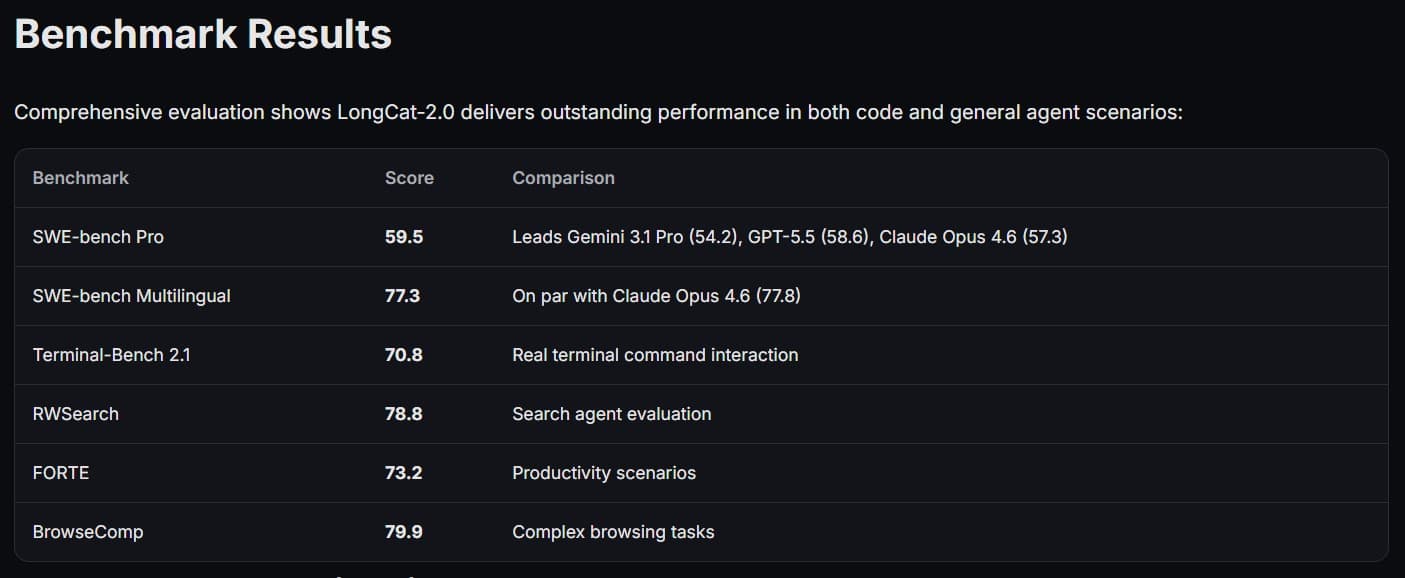
Китайская компания Meituan объявила о релизе LongCat-2.0 — крупной языковой модели нового поколения с 1,6 трлн параметров и экстремально длинным контекстом до 1 млн токенов. Ключевая особенность релиза заключается в том, что полный цикл — от предобучения до инференса — выполнен на вычислительном кластере из 50 тыс. отечественных ASIC-ускорителей, что делает систему одним из крупнейших публично описанных примеров полного обучения LLM на национальном железе.Под ASIC (application-specific integrated circuit) в данном случае понимаются специализированные вычислительные чипы, оптимизированные под задачи машинного обучения, а не универсальные GPU. По косвенным признакам, включая использование коммуникационной библиотеки HCCL (Huawei Collective Communication Library), инфраструктура может быть связана с аппаратной экосистемой Huawei, хотя поставщик ускорителей официально не раскрывается.Архитектура LongCat-2.0 рассчитана на работу с агентными сценариями — задачами, где модель пишет и редактирует код, использует инструменты, взаимодействует с API и реализует многошаговые цепочки рассуждений. Внутренний корпус обучения превышает 30 трлн токенов и включает мультиязычные данные и программный код.Источник: MeituanОдним из ключевых технических элементов стала LongCat Sparse Attention (LSA) — механизм разреженного внимания, который вместо полного попарного сравнения токенов выбирает только наиболее значимые элементы контекста. Это позволяет масштабировать обработку до 1 млн токенов, снижая вычислительную сложность с квадратичной до близкой к линейной в практической реализации.Дополнительно модель использует динамическую активацию параметров в диапазоне примерно 33–56 млрд активных весов на токен (архитектура Mixture of Experts). Простые токены обрабатываются с минимальными вычислениями, тогда как сложные автоматически задействуют больше вычислительных ресурсов. Такой подход снижает стоимость инференса при сохранении качества на сложных задачах.Отдельно заявлена схема MOPD (Multi-Teacher On-Policy Distill) — метод дистилляции, при котором несколько специализированных «экспертных» подмоделей обучают единый чекпоинт. В LongCat-2.0 выделяются три группы: агентные эксперты (работа с инструментами и API), reasoning-эксперты (многошаговая логика и STEM-задачи) и интерактивные эксперты (следование инструкциям и снижение галлюцинаций).По заявленным бенчмаркам LongCat-2.0 показывает конкурентоспособные результаты в задачах создания кода и агентного взаимодействия. В SWE-bench Pro модель набирает 59,5 балла, опережая Gemini 3.1 Pro и находясь близко к уровню GPT-5.5 и Claude Opus последних версий, при этом оставаясь ниже лидеров общего назначения. Сильные результаты также фиксируются в Terminal-Bench 2.1 и задачах поиска и веб-агентов.Практические демонстрации включают автоматическое построение SQL-агентов, рефакторинг больших кодовых баз под новые API, генерацию полноценных веб-приложений по одному описанию, создание интерактивных 3D-сцен на Three.js и многоагентные системы генерации текстов с контролем согласованности на длинных горизонтах контекста.В совокупности LongCat-2.0 демонстрирует сразу два сдвига: переход к триллионным моделям, обученным на полностью локальной аппаратной базе, и смещение фокуса в сторону агентных сценариев, где ключевой метрикой становится не только качество текста, но и способность модели выполнять сложные цепочки действий в длинном контексте. Это усиливает конкуренцию между китайской и западной экосистемами LLM и показывает, что масштабное обучение на национальных вычислительных кластерах становится практической реальностью, а не экспериментом.
{kind=link}